
Media
Healthcare Insights from Professionals
We constantly leverage our extensive industry knowledge and expert relationships to reveal the latest trends across MedTech markets in order to bring you actionable news and insights.
Latest Articles

Explore the Q4 2025 IVD Performance Scorecard to see how major acquisitions and structural shifts are redefining the global diagnostics industry. Analyze how 11 leading companies are navigating China’s procurement reforms, the shift toward specialty assays, and the high-stakes race in rapid antimicrobial susceptibility
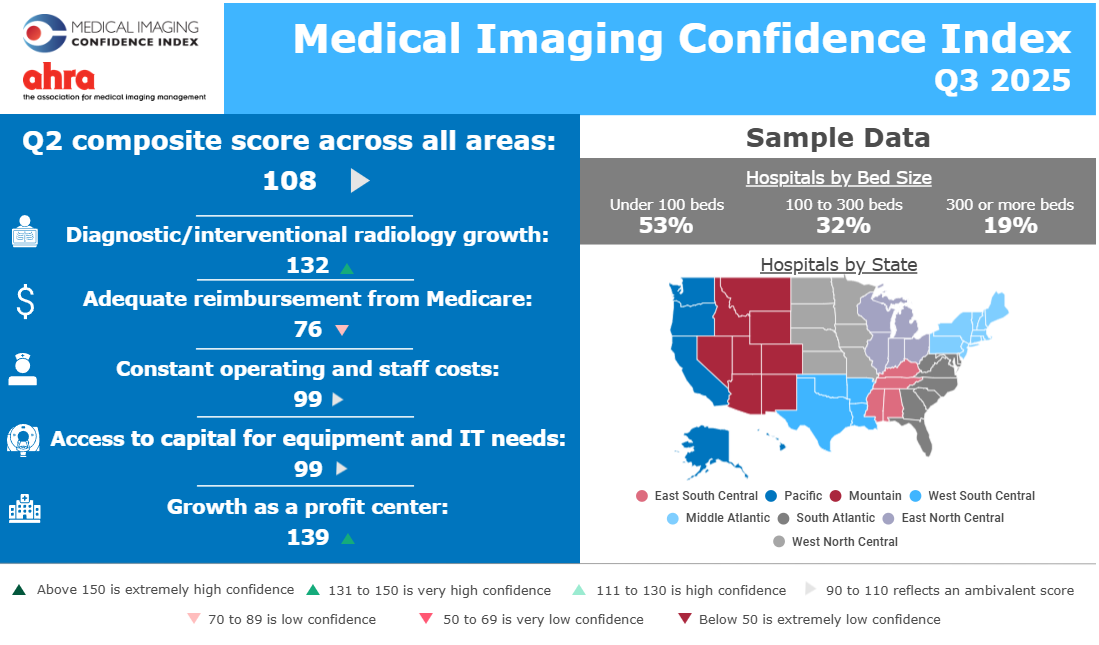
2025 MICI Q4 Shows S mall Increase in Overall Confidence from Q3 2025
Discover how ESG is reshaping healthcare—from sustainable imaging and energy‑efficient design to equity and governance strategies driving industry transformation.
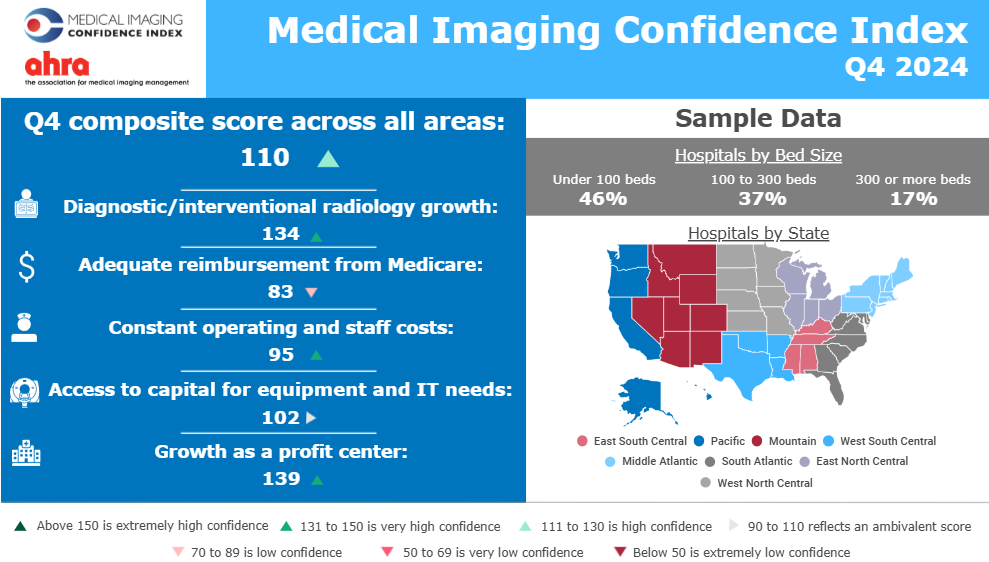
2025 MICI Q3 Shows Less Confidence in Reimbursement and Capital Access

The imagePRO panel shows larger imaging departments are more proactive on 2025 tariff risks, while smaller teams are more likely to take no immediate action.

Learn when to rely on your in-house marketing research team and when to bring in an external agency to gain deeper, unbiased insights that drive confident decisions across your product lifecycle.

Discover key questions to ask when selecting a marketing research partner for your healthcare or MedTech company to ensure reliable, actionable insights.

The imagePro Market Pulse (iPMP) is a series of insights on the US radiology market provided by The MarkeTech Group.

Learn how Conjoint Analysis can help MedTech companies make data-driven decisions by understanding customer preferences and optimizing product offerings.

Learn effective healthcare market segmentation strategies, including patient segmentation, to enhance targeted marketing in healthcare.

Contact Us
We would love to hear from you. Send a message via our contact page and we will get back to you as soon as we can.
